August 23, 2016
by Yousuf Hasan
We had a great afternoon with the NFD team as we walked them through our vision, design principles and demos of the Brocade Workflow Composer. We had productive discussions and got good, candid feedback. Caffeine and sugar kept everyone’s critical abilities to the max. There’s 4 separate video sessions…here’s what happened:
Kick-off, Brocade Automation Vision, Overview
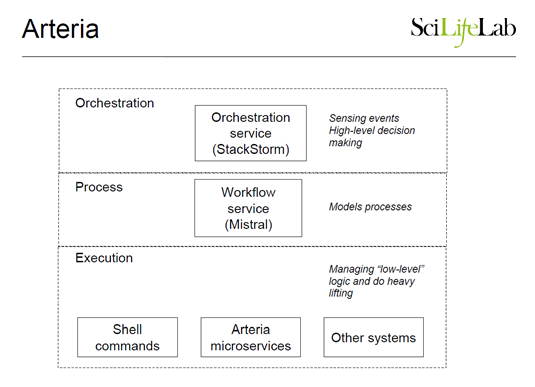
Jason kicked off the event by talking about the fact that Brocade has been focused on delivering agility and automation to customers for years…storage area networking, VCS Fabrics, etc. Brocade Workflow Composer (BWC) is the latest step in this journey towards agility and automation, where open source and DevOps are key driving factors. Devops methodologies have been applied to applications and compute successfully by Google, Facebook, Amazon and similar webscale companies. BWC supports this culture through open source technologies and community-centric approach but adds network automation to the mix. And BWC has a strong starting point because it’s based on Brocade’s acquisition of StackStorm.
StackStorm is a proven, open source platform and will continue to stay so. BWC will be the Enterprise grade version with Enterprise bells and whistles such as RBAC/LDAP and Brocade Technical Support. Brocade wants to bring DevOps principles to networking. BWC is a micro-services based, off-box automation platform that can automate the network lifecycle, other IT domains such as compute, storage, applications and operations all of which form essential components of a modern IT service. Network lifecycle automation spans automated provisioning, automated validation, automated troubleshooting and automated remediation – components critical in achieving agility and operating efficiency.
StackStorm Fundamentals
Dmitri Zimine, ex-CTO of StackStorm, defines StackStorm as event driven automation in a DevOps manner. Dmitri talked about automation not only for day 0 provisioning of IT services, but also the need to manage day 2 operations such as troubleshooting and remediation. Leaders in the IT industry already automate day 2 operation in-house, such as FBAR from Facebook. However, none are available to the public as open source projects or commercial products.
Dmitri described the founding of StackStorm and the product’s design principles. Sensors are integration points that tie inputs from various domains and allow BWC to automatically react to one or more events of interest and take actions, based on IFTTT (if-this-then-that) programmatic logic. BWC has 700+ community users who are contributing integration packs and workflows to the community delivering nearly 2000 points of integration for others to use (check out StackStorm’s Git repository). These include integrations into public cloud, containers, OpenStack, monitoring services, other automation systems and even integrations to your Tesla. The community-centric angle provides BWC with a rich set of existing cross-domain integrations to build on.
Dmitri showed a cool interactive demo and the BWC Design UI. The interactive used a StackStorm workflow to throw all StackStorm related tweets from NFD12 events to a StackStorm Slack channel to highlight the use of workflows, sensors, actions, and cross-domain integration. The BWC Design UI demonstration showed how users can visually tweak workflows via drag & drop and visual navigation –great for those just getting started in developing workflows.
Brocade Workflow Composer – Part I
Yousuf, Sr, Manager, Product Management for Workflow Composer, added to the StackStorm foundation by focusing on the network automation lifecycle and demoing the automated provisioning of a 3-Stage IP Fabric on 7 VDX switches in less than 15 minutes !
First, the demo builds an IP Fabric with BGP EVPN, following the same design principles that webscale companies such as Facebook and Microsoft use. Once the workflows are tested, they’re error free and can be reused. Manual provisioning of the same IP Fabric can take days (or more if engineers make mistakes).
Second, the ability to automate the entire network lifecycle. Yousuf highlighted the fact that while the demo is focused around IP Fabric provisioning, the key value for customers is in validation, troubleshooting and remediation of datacenter and other networking use cases. The NFD12 bloggers also agreed with this point because while fabric provisioning automation makes a good demo, people don’t build fabrics everyday.
The real value is in event-driven automation where a workflow can be triggered by a sensor watching for network events such as link errors on a port-channel or environmentals going whacko. The sensor uses IFTTT to trigger a troubleshooting workflow to collect information and based on that, initiate a remediation workflow that uses BWC actions to steer traffic off the failing switch. All done without a single human involved.
The audience also highlighted the fact that network engineers lag in the programming/DevOps space and a network centric UI for network lifecycle automation will benefit the networking guys. This is where BWC’s turnkey, customizable workflows come in. Turnkey workflows provide out-of-the-box automation but are customizable to enable network engineers to adapt them to meet unique needs.
Brocade Workflow Composer – Part II
Lindsay Hill, Sr. Product Manager Workflow Composer, pulled it all together by demonstrating how BWC uses StackStorm’s event-driven, cross-domain automation to detect and remediate a critical IT service, informing and involving humans only as needed. The demo automated disk space remediation on a Linux webserver by using Sensu as a monitoring sensor which triggers a BWC workflow when the Linux server runs low on disk. This workflow clears a logs directory on the disk to remediate low disk space issue while the success or failure of this workflow is reported to Slack via ChatOps integration.
To bring all this automation back to helping network operators, Lindsay also talked about automated BGP troubleshooting and remediation workflows which can turn a 3 am call into a 9 am e-mail review.
Lastly, Lindsay emphasized the fact that StackStorm open source project features and community integration packs are critical success factors for Brocade’s automation journey. StackStorm community users and contributors are able to implement event-driven, cross-domain automation. Using StackStorm as the foundation, BWC users are able to apply these principles to networking integrated with enterprise security and the full backing of technical support. BWC and StackStorm are available as RPM and deb packages.
The post Summary – Brocade Workflow Composer at NFD 12 appeared first on StackStorm.
 StackStorm Web Interface
StackStorm Web Interface BWC Web Interface
BWC Web Interface Workflow Designer
Workflow Designer